
How we made it
Overview
The Global Medieval Sourcebook was originally built as a Drupal 7 site, with a custom module to generate Versioning Machine-based displays for uploaded TEI files. While the Drupal UI was convenient for entering metadata while the project was under active development, its ongoing high-touch upkeep made it a poor choice for long-term sustainability. Consequently, we chose to migrate to a static website environment as the project concluded.
Options Considered
Wax
We initially explored Wax as a framework for the static site, given the general similarity of our data to the content Wax is designed for. The documents in GMS each had a landing page with an accompanying image and structured metadata, which maps nicely to the content Wax expects (spreadsheets of structured metadata and a pointer to an image file). We considered mapping GMS collections to Wax’s Exhibits. Ultimately, however, we decided we wanted to keep even the static site generator infrastructure as minimal as possible, and Wax’s support for IIIF image display and creating image derivatives was more than we needed for GMS. The team also had some particular design ideas in mind, and we were not confident in our ability to implement those in Wax using Liquid (templating language) and SASS (stylesheets). Instead, we chose a Jekyll theme that was fairly close to what we were looking for, to reduce the number of design features we needed to implement ourselves.
DH Literacy Guidebook
The Carnegie Mellon University Digital Humanities Literacy Guidebook (DHLG), developed by Scott Weingart, Susan Grunewald, Matthew Lincoln et al. includes a number of different content display types, dropdown menus, a static sidebar, and a mobile-friendly theme. The project videos landing page was a good model for what we wanted to offer users for browsing, and we imagined repurposing the table of contents sidebar on that page for text metadata. The code for the site was available on GitHub, and Matthew Lincoln was generous about answering a few questions about how various site features were implemented. The only major new feature that we needed to implement was adding tags (described below).
Data migration
Original data structure
On the original Drupal site, there was a Drupal node (page of structured data and metadata) for each text. A TEI-encoded version of the text was linked to the page, and another link took viewers to a static HTML page with a two-column text display, generated by the Versioning Machine. Each text also had a thumbnail image.

For the static version of the site, we decided to forego the Versioning Machine display (see “Text Display”, below), but we still needed to export the text metadata (e.g. things like author, language, date, credits, suggested citation) and data (introduction to the text, introduction to the source, about the edition, further reading). We also needed to generate a thumbnail image that would be compatible with the DHLG’s gallery view, and export that image, the full size image, and the image caption.
The full text itself was not part of the original text pages (only on the static Versioning Machine pages that were not connected to the site’s search index). For the new site, we wanted to make texts findable using the full text contents, but not display that full text on the page. To do this, we would also need to extract the full text without TEI markup from the XML files, and include it as part of the markdown file frontmatter that would be included in the search index created for the site.
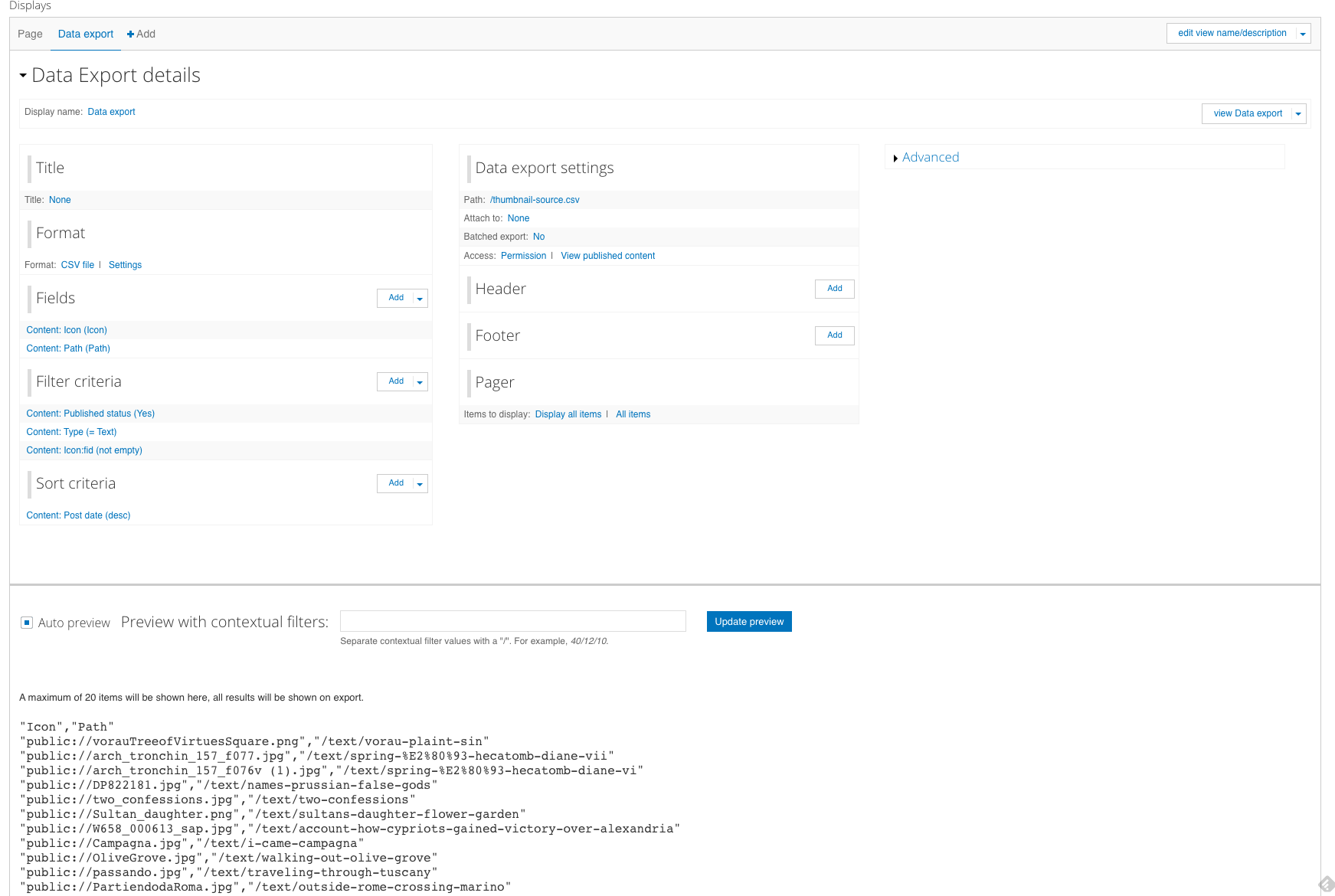
Drupal data export
We used the Views Data Export module for Drupal to generate a CSV with all of the data and metadata, with the exception of the images.
The export was configured to retain HTML tags in order to correctly render the bibliography.
A separate view using Views Data Export provided a mapping from the image filename in the Drupal filesystem (which often included things like spaces or special characters) to the text the image was associated with. We used this to bulk-rename the image files
Data cleaning
Some of the text coming out of Drupal needed to be reformatted to work better as part of the frontmatter of a markdown file. This included things like language names, collection names, and page and image paths. For the language names and collection names in particular, the text coming out of Drupal is human-readable, but we needed to convert these into more machine-friendly versions, that could be mapped to human-readable formats in the frontmatter for each category page in Jekyll (see “Adding Tags”, below). For instance, the collection “Love Songs of the Medieval World: Lyrics from Europe and Asia” became “love-songs” in the frontmatter of each text in that collection, and the frontmatter for love-songs.md (in the _textcollections folder) included both the identifier love-songs and the title “Love Songs of the Medieval World: Lyrics from Europe and Asia”.
If we expected to be migrating texts from Drupal to Jekyll on an ongoing basis, we would have automated most or all of this step. However, we intended to only do it twice: first as a proof-of-concept, and a second time once the data entry was complete. We estimated it would be more efficient to just do it manually, using OpenRefine for bulk changes.
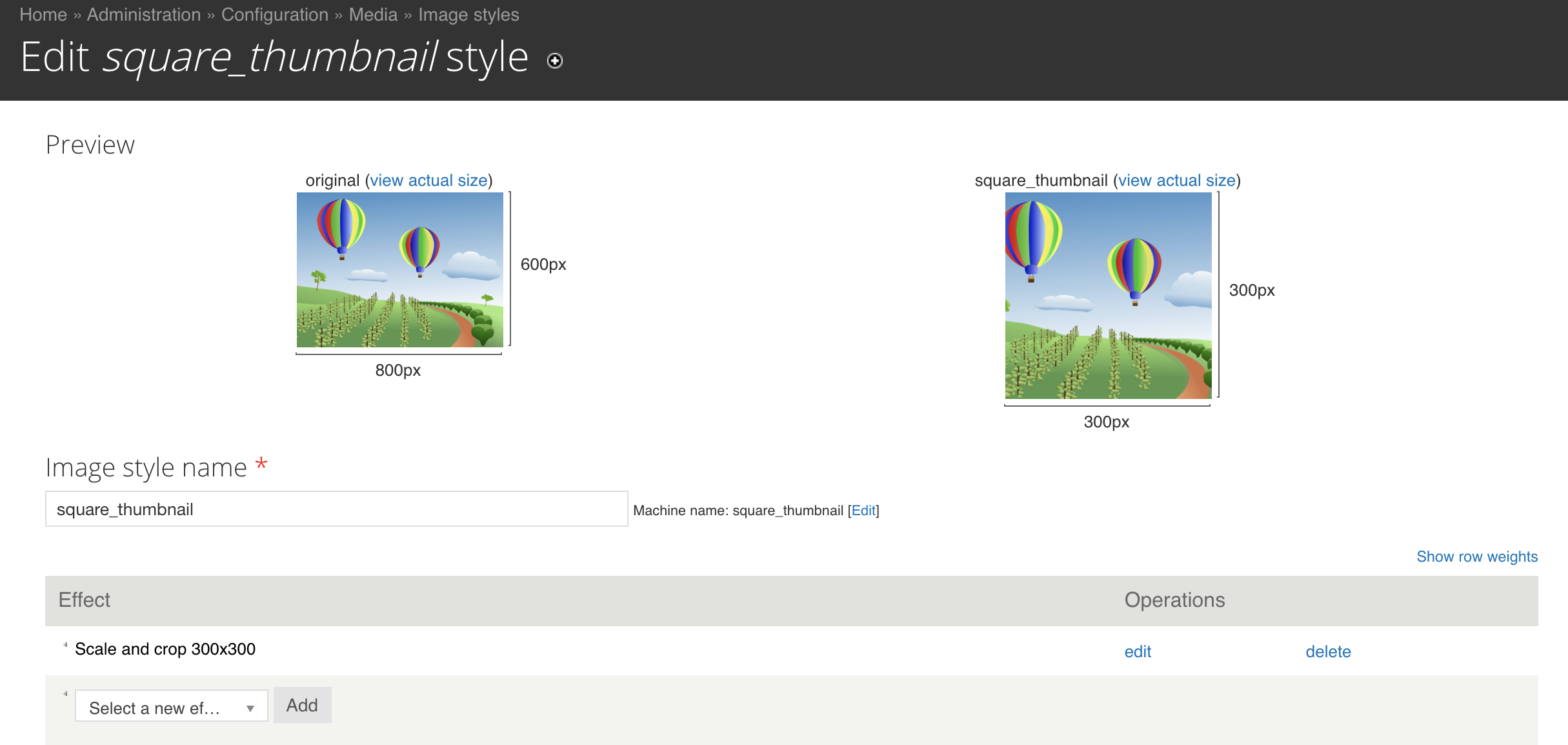
Image thumbnails
For the text browsing page (based on the DHLG project videos page) we needed to have uniform, square thumbnail images, or else the texts would appear misaligned. Drupal has the ability to define custom “media styles”, and it can generate derivatives of images on the site using the properties you define in a media style. We set up a small square media style, and created a page (using Drupal’s Views module) that would display all the icon images in that style.
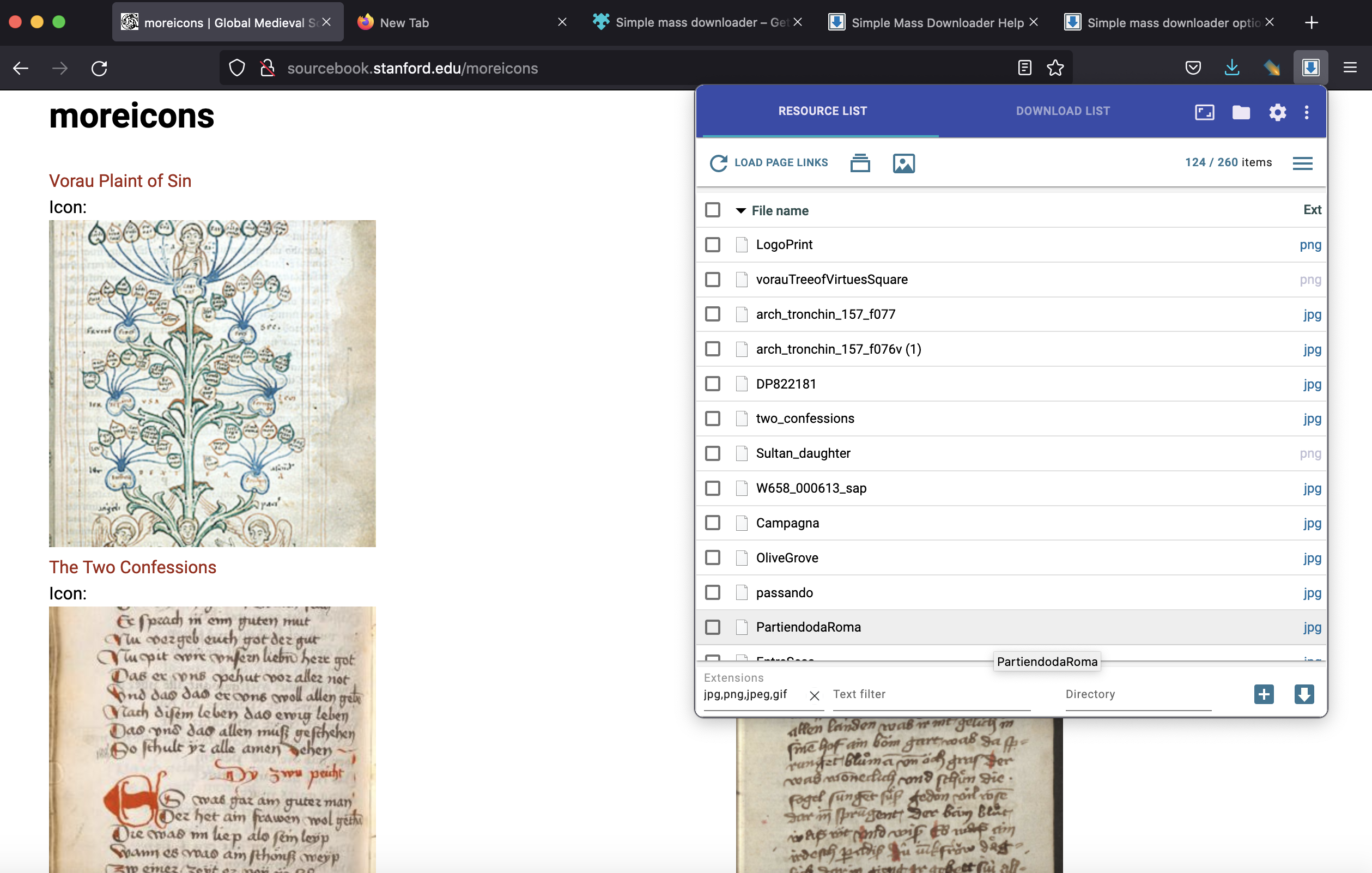
Next, we went to that page and used the Simple Mass Downloader extension for Firefox, filtering for just image files, to download all the thumbnail images.
Renaming Images
We wanted all the files connected to a text to share a single identifier. Unfortunately, the identifier we wanted to use for the texts was not necessarily part of the Drupal export. We manually modified the closest value from the Drupal export to serve as the universal identifier for the text. Once we had that value in our metadata spreadsheet, we were able to use Python code that we wrote to replace the old image filenames (which were often quite long and involved characters that can cause glitches with servers) with the new identifier. That code is in our Jupyter notebook, under the section “Image Renamer”.
Text Display
The Versioning Machine text display component of the original Drupal site involved static HTML pages themed to match the dynamically-generated Drupal pages. Rethinking the website framework also provided us with an opportunity to reflect on the best way to handle the text display. Versioning Machine was an awkward fit for GMS text display, because the project displays translations of texts, rather than versions of the text (i.e. in the same language, with some minor variation). As a result, the lines sometimes were not well aligned between the two versions, making it difficult to navigate and compare even using the Versioning Machine hover-and-highlight functionality. Alignment became even more complicated as we introduced texts written in right-to-left scripts. While the Versioning Machine’s static HTML pages that would be in keeping with our new technical approach, we had not been successful in developing a print-friendly CSS stylesheet that could take the Versioning Machine HTML and transform it into an aesthetically pleasing, easy-to-read, 2-column layout. Given the pedagogical goals of the GMS project (e.g. offering texts and translations that can easily be used in the classroom), we decided to invest time in producing manually typeset PDF versions, to ensure a high-quality printable version for each text.
The only user-visible form of the text is the PDF. However, we did want the search function to be able to search the full text, even if we do not display it. (In the Drupal site, we had added a free-form “tags” field that was inconsistently applied, but was meant to be a proxy for full-text search.) To do this, we needed to reformat the TEI text so it could go into the frontmatter for the text markdown file, in a single line with no TEI markup.
Removing TEI
We wrote Python code that went through all of our TEI files (which had already been renamed according to the unique identifier for their text), and created a .txt file derivative. We extracted lines with the <lem> (lemma) and <rdg> (reading) tags used to encode lines of the original and the translation, respectively, and removed all tags from those lines. We then combined all these lines into a single line of text and saved it to the .txt file.
Creating Static Text Pages
We wrote Python code that went through each row of our metadata spreadsheet (which corresponded to a single text), and generated a markdown file that would include all metadata, a pointer to the text image, various file downloads, and the text description on the page itself. Typically, each of these things corresponded to a column in our metadata sheet; in our Jupyter notebook, we have a key mapping column numbers to data. The last item in the frontmatter is the full text, which we pull from the .txt files generated from the TEI files (as described above).
Adding Tags
Drupal 7 provides an easy way to make metadata into a clickable tag, where you can click on the text of the tag to see a page with all the items tagged in that way. The DH Literacy Guidebook did not include tagging functionality out-of-the-box. In Jekyll, you can implement this as “categories”, which you define in the “Collections” section of the Jekyll _config.yml file. Each group of things that makes up a “category” (for us: region, period, and text collection) gets its own folder prefixed with an underscore, and in that score, there’s a markdown file for each tag in that category (for us: our “periods” folder includes 7th_century.md, 8th_century.md, etc.) As described above, the frontmatter for each of those markdown files includes its unique identifier and a more human-friendly title.
Once the tags are defined as a set of Jekyll “collections”, you need to write code into a Jekyll layout or include to turn the tag-identifiers into links to the right pages. With help from Matthew Lincoln, we wrote code to loop through all the collection identifiers present in the frontmatter for a text, and then display the title found in the collection’s frontmatter along with a link to the tag page, rather than just displaying the tag identifier:
{% if page.textcollections And page.textcollections != “” And page.textcollections != nil %}
{% assign listtextcollections = page.textcollections %}
{% for listtextcollection in listtextcollections %}
{% for textcollection in site.textcollections %}
{% if listtextcollection contains textcollection.identifier %}{{textcollection.title}}
{% endif %}
{% endfor %}
{% unless forloop.last %} {% endunless %}
{% endfor %}
{% if %}
Other Design Changes
We made some changes to the color palette in the _01_settings_colors.scss SASS file, and to make the top bar look and act more like the old Drupal site, Karin Dalziel made some changes to main.scss, as well as _top-bar.scss in foundation-components.